
上一期我们讲完了if和if else
现在我们来讲一下switch语句
这个关键字switch用于比较复杂的选择
switch(表达式){
case 常量表达式1: 语句1;
case 常量表达式2: 语句2;
…
case 常量表达式n: 语句n;
default: 语句n+1;
}
意思就是switch先计算switch后面的表达式的值,然后和case后面的表达式逐一匹配,若都无法匹配那么就会调用default后面的语句
这里我们再介绍一下与之相关的其他关键字,switch语句也可用于循环
goto语句
goto 可以用作跳转标签,再做goto跳转之前得现在前面定义一个标签
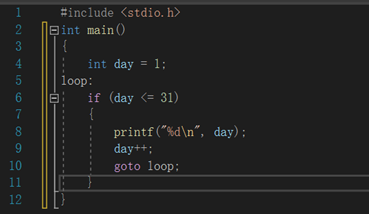
类似于如此后面我们说到循环还会强调这几个关键字
下面我写一个switch语句的实例

这里我本来是准备做一个输入函数的,可惜我们还没有说到输入函数后面说到函数的定义的时候我们会说到一些其他的概念
下面我们来说一下while循环
while (表达式)
{
语句;
}
当表达式内的逻辑值为真时,执行花括号内的语句(我们在说循环的时候循环关键字内的语句我们后面称作循环体)
这个循环结构是最简单的循环结构,如果我们把表达式换成1或者任意一个非零值(因为非零值的逻辑值都是真那么这个循环将会一直执行下去)
实例如下图

do while 循环
do
{
语句;
}
while (表达式);
注意while后面的分号是不能省略的,这个与while循环的区别很简单,就是先执行循环体的内容在让while后面的表达式做判断
也就是说,不管怎么样do while循环不管怎么样都会执行一次循环体的内容
for 循环的一般形式为:
for(表达式1; 表达式2; 表达式3){
语句块
}
它的运行过程为:
1) 先执行“表达式1”。
2) 再执行“表达式2”,如果它的值为真(非0),则执行循环体,否则结束循环。
3) 执行完循环体后再执行“表达式3”。
4) 重复执行步骤 2) 和 3),直到“表达式2”的值为假,就结束循环。
上面的步骤中,2) 和 3) 是一次循环,会重复执行,for 语句的主要作用就是不断执行步骤 2) 和 3)。

所有的循环语句之间都可以互相嵌套使用
这里我举一个例子,如果在使用for循环的时候,懒得去判断循环终止条件具体是什么
那么我们可以把for循环的三个表达式都不写(表示死循环),但是我们不能让死循环一直循环下去

这样的循环会一直执行下去,这里我们在循环体里面加入一个if语句

类似于这样这样循环体每一次都会做一次比较i是不是等于20;当等于20的时候就会被goto语句跳出循环(也可以尝试使用break语句)
学计算机的时候永远要相信一个观念,计算机是死的,你不告诉它要做什么他就不会做什么直到计算机宕机
函数
函数有c语言库和头文件里面定义的官方函数(这一类我们称作库函数)还有用户自定义的函数
函数的定义
函数的类型 function(参数1,参数2….)
{
函数体
}
函数的参数也可以没有,也可以有
函数的类型就和数据的类型意义有int void float double long short这里我们没有说过的关键字就是void,void表示的就是函数没有返回值void类型可以没有返回值,返回值可以是函数的本身(这样就是递归传参)
我们定义变量的时候有一个作用范围和生命周期,我们在main函数定义的变量只能在main函数中调用,我们定义了一个函数,这个函数里面定义的变量就叫做局部变量,那么全局变量就是在编译器中直接定义的变量例如

像我们刚刚的类型可以直接声明函数并且定义函数是干什么的,
那么我们有没有什么办法只声明一个函数呢
答案是有的
函数的类型 function(参数1,参数2)
这里和上面我们用到的function指的是函数名,函数名和变量名的要求一样,这样我们就只声明了一个函数,但是我们还没有定义里面的内容
在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
int max(int, int);
下面是实例

如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。
形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。
当调用函数时,有两种向函数传递参数的方式:
传值调用 该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数不会影响实际参数。
引用调用 通过指针传递方式,形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。(关于指针下一期再说)
下面我们说一下数组
C 语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。
数组的声明并不是声明一个个单独的变量,比如 runoob0、runoob1、…、runoob99,而是声明一个数组变量,比如 runoob,然后使用 runoob[0]、runoob[1]、…、runoob[99] 来代表一个个单独的变量。
所有的数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。一个数组中的所有元素都是同一个类型的
在 C 中要声明一个数组,需要指定元素的类型和元素的数量,如下所示:
type arrayName [ arraySize ];
这叫做一维数组。arraySize 必须是一个大于零的整数常量,type 可以是任意有效的 C 数据类型。例如,要声明一个类型为 double 的包含 10 个元素的数组 balance,声明语句如下:
double balance[10];
在 C 中,您可以逐个初始化数组,也可以使用一个初始化语句,如下所示:
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};大括号 { } 之间的值的数目不能大于我们在数组声明时在方括号 [ ] 中指定的元素数目。
如果您省略掉了数组的大小,数组的大小则为初始化时元素的个数。因此,如果:
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};您将创建一个数组,它与前一个实例中所创建的数组是完全相同的。下面是一个为数组中某个元素赋值的实例:
balance[4] = 50.0;上述的语句把数组中第五个元素的值赋为 50.0。所有的数组都是以 0 作为它们第一个元素的索引,也被称为基索引,数组的最后一个索引是数组的总大小减去 1
数组元素可以通过数组名称加索引进行访问。元素的索引是放在方括号内,跟在数组名称的后边。例如:
double salary = balance[9];上面的语句将把数组中第 10 个元素的值赋给 salary 变量。下面的实例使用了上述的三个概念,即,声明数组、数组赋值、访问数组:
实例

数组还有二维数组二维数组
二维数组的定义
二维数组定义的一般形式是:dataType arrayName[length1][length2];其中,dataType 为数据类型,arrayName 为数组名,length1 为第一维下标的长度,length2 为第二维下标的长度。
我们可以将二维数组看做一个 Excel 表格,有行有列,length1 表示行数,length2 表示列数,要在二维数组中定位某个元素,必须同时指明行和列。例如:int a[3][4];
定义了一个 3 行 4 列的二维数组,共有 3×4=12 个元素,数组名为 a,即:a[0][0], a[0][1], a[0][2], a[0][3]
a[1][0], a[1][1], a[1][2], a[1][3]
a[2][0], a[2][1], a[2][2], a[2][3]
如果想表示第 2 行第 1 列的元素,应该写作 a[2][1]。
也可以将二维数组看成一个坐标系,有 x 轴和 y 轴,要想在一个平面中确定一个点,必须同时知道 x 轴和 y 轴。
二维数组在概念上是二维的,但在内存中是连续存放的;换句话说,二维数组的各个元素是相互挨着的,彼此之间没有缝隙。那么,如何在线性内存中存放二维数组呢?有两种方式:一种是按行排列, 即放完一行之后再放入第二行;
另一种是按列排列, 即放完一列之后再放入第二列。
在C语言中,二维数组是按行排列的。也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节,整个数组共占用 4×(3×4)=48 个字节。
实例如下这是我在网上找的一个题目然后自己做的


这个是题目
其中我们用到了scanf函数 scanf函数表示输入
这里我们可以看到scanf函数和printf函数都用到了%d的东西\n我们之前说过了是转义字符表示回车
那么%d表示什么呢,表示的是输出格式(输入格式)
%d表示的是输出d格式的字符或者数据d格式表示的是十进制整型(也有的书说是%d格式)
下面是输出格式
1、%d 按整型数据的实际长度输出。
2、%md m为指定的输出值的宽度。如果数据的位数小于m,则左端补以空格,若大于m,则按实际位数输出。
3、%0md 用这种格式时,左端用0来代替空格
4、%-md m为指定的输出值的宽度。如果数据的位数小于m,则右端补以空格,若大于m,则按实际位数输出
5、%ld 输出长整型数据。
f格式 实数(包括单、双精度),以小数形式输出。
1、%f 不指定宽度,整数部分全部输出并输出6位小数。
2、%m.nf 输出共占m列,其中有n位小数,如数值宽度小于m左端补空格。
3、%-m.nf 输出共占m列,其中有n位小数,如数值宽度小于m右端补空格。
e格式:以指数形式输出实数。有以下用法:
1、%e 数字部分(又称尾数)输出6位小数,指数部分占5位或4位。
2、%m.ne和%-m.ne m、n和”-”字符含义与前相同。此处n指数据的数字部分的小数位数,m表示整个输出数据所占的宽度
g格式:自动选f格式或e格式中较短的一种输出,且不输出无意义的零
s格式:用来输出一个串。用法如下:
1、%s:例如:printf(“%s”, “CHINA”)输出”CHINA”字符串(不包括双引号)。
2、%ms:输出的字符串占m列,如字符串本身长度大于m,则突破获m的限制,将字符串全部输出。若串长小于m,则左补空格。
3、%-ms:如果串长小于m,则在m列范围内,字符串向左靠,右补空格。
4、%m.ns:输出占m列,但只取字符串中左端n个字符。这n个字符输出在m列的右侧,左补空格。
5、%-m.ns:其中m、n含义同上,n个字符输出在m列范围的左侧,右补空格。如果n>m,则自动取n值,即保证n个字符正常输出。
这就是常见的输出格式(输入格式)
c语言程序很少用到输入函数了,基本上很多时候c语言都用在网络信息处理,数据处理,底层架构等,但是我们如果对一个程序反编译之后可能还会看到scanf函数(反编译是我们这三期的初衷)
C 字符串
在 C 语言中,字符串实际上是使用空字符 \0 结尾的一维字符数组。因此,\0 是用于标记字符串的结束。
空字符(Null character)又称结束符,缩写 NUL,是一个数值为 0 的控制字符,\0 是转义字符,意思是告诉编译器,这不是字符 0,而是空字符。
下面的声明和初始化创建了一个 RUNOOB 字符串。由于在数组的末尾存储了空字符 \0,所以字符数组的大小比单词 RUNOOB 的字符数多一个。
这些是常见的字符串处理函数
1 strcpy(s1, s2);
复制字符串 s2 到字符串 s1。
2 strcat(s1, s2);
连接字符串 s2 到字符串 s1 的末尾。
3 strlen(s1);
返回字符串 s1 的长度。
4 strcmp(s1, s2);
如果 s1 和 s2 是相同的,则返回 0;如果 s1<s2 则返回小于 0;如果 s1>s2 则返回大于 0。
值得注意的是第四个比较两个字符串的时候,两个字符串必须是相同长度,而且比较方式是按照ASCII字符表来比较的
附录
在我的预期中,下一期会出结构体,指针,还有部分头文件等,关于其他c语言的知识这里将不会阐述可以个人私信问我(我是学的c++,出这两期的时候还是有点吃力)在反编译的时候我们最容易看到的也就是c语言的东西,这里我们说到字符串处理函数和scanf函数一共五个函数,这五个函数是很容易引发缓冲区溢出漏洞的关于缓冲区溢出漏洞看前面的永恒之蓝(一般编程的书籍上不会说这些)



没有回复内容